搜索引擎核心技术详解5—检索模型与搜索排序

检索模型是搜索引擎排序的理论基础,用来计算网页和用户查询的相关性。
几种常用的检索模型包括:布尔模型、向量空间模型、概率模型、语言模型及最近几年兴起的机器学习排序算法。
目前大部分商业搜索引擎采用概率模型作为相关性排序模型,而BM25则是目前效果最好的概率检索模型。
精确率和召回率是评价检索系统的常用指标,而对于搜索引擎来说,精确率尤为重要。
可以将检索模型看做是:在用户需求已经很明确地由查询词表征的情况下,如何找出内容相关的文档。
搜索结果排序是搜索引擎最核心的构成部分,很大程度上决定了搜索引擎的质量好坏及用户接受与否。尽管搜索引擎在实际结果排序时融合了上百种排序因子,但最重要的两个因素还是用户查询和网页的内容相关性及网页链接情况
判断网页内容是否与用户查询相关,这依赖于搜索引擎所采用的检索模型。
检索模型理论研究都存在理想化的隐含假设,即假设用户需求已经通过查询非常清晰明确地被表达出来,所以检索模型的任务不牵扯到对用户需求建模。很明显这与事实相距甚远,即使是相同的查询词,不同用户的需求目的可能差异很大,而检索模型对此无能为力。
所以可以将检索模型看做是:在用户需求已经很明确地由查询词表征的情况下,如何找出内容相关的文档。如果查询词不能精确代表用户真实需求,那么无论检索模型再优秀也无济于事,这是为何搜索引擎发展到目前阶段,重点转向了填补用户真实需求和发出的查询词之间的鸿沟的原因,此发展趋势有其必然性。
1、布尔模型
布尔模型是检索模型中最简单的一种,其数学基础是集合论。在布尔模型中,文档与用户查询由其包含的单词集合来表示,两者的相似性则通过布尔代数运算来进行判定。
用户查询一般使用逻辑表达式,即使用“与/或/非”这些逻辑连接词将用户的查询词串联,以此作为用户的信息需求的表达。比如用户希望查找和苹果公司相关的信息,可以用以下逻辑表达式来作为查询:
苹果AND(乔布斯ORiPad2)
布尔模型简单直观,但是正是因为其简单性,导致一些明显的缺点。只要文档满足逻辑表达式,就会被认为是相关的,其他文档被认为是不相关的,即其结果输出是二元的,要么相关要么不相关,至于文档在多大程度上和用户查询相关,能否按照相关程度排序输出搜索结果?这些布尔模型都无能为力,所以无法对搜索结果根据相关性进行排序,其搜索结果过于粗糙。同时,对于普通用户来说,要求其以布尔表达式的方式构建查询,无疑要求过高。
2、向量空间模型
向量空间模型历史悠久,最初由信息检索领域奠基人Salton教授提出,经过相关学科几十年的探索,目前已经是非常成熟和基础的检索模型。向量空间模型作为一种文档表示和相似性计算的工具,不仅仅在搜索领域,在自然语言处理、文本挖掘等诸多其他领域也是普遍采用的有效工具。
1)文档表示
作为表示文档的工具,向量空间模型把每个文档看做是由t维特征组成的一个向量,特征的定义可以采取不同方式,可以是单词、词组、N-gram片段等多种形式,最常用的还是以单词作为特征。其中每个特征会根据一定依据计算其权重,这t维带有权重的特征共同构成了一个文档,以此来表示文档的主题内容。
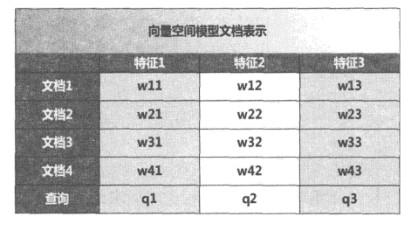
比如对于文档2来说,由3个带有权重的特征组成{w21,w22,w23},w21代表了第2个文档的第1维特征的权重,其他的权值代表相似含义。在实际应用系统中,维度是非常高的,达到成千上万维很正常,图中为了简化说明,只列出3个维度。在搜索这种应用环境下,用户查询可以被看做是一个特殊的文档,将其也转换成t维的特征向量。
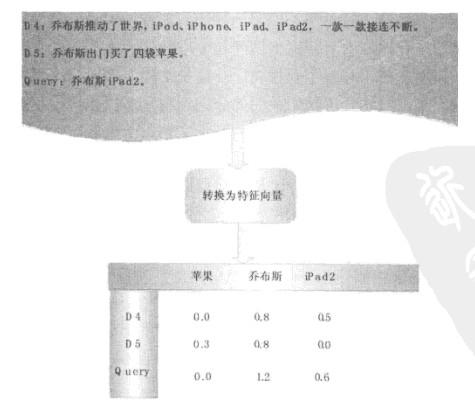
是具体的文档表示实例,对于文档D4和D5及用户查询,通过特征转换,可以将其转换为带有权值的向量表示。
2)相似性计算
将文档转换为特征向量后,就可以计算文档之间或者是查询和文档之间的相似性了。对于搜索排序这种任务来说,给定用户输入的查询,理论上应该计算查询和网页内容之间的“相关性”,即文档是否和用户需求相关,之后按照相关程度由高到低排序。向量空间模型将问题做了转换作为相关性的替代,按照文档和查询的相似性得分由高到低排序作为搜索结果,但是要注意,两者并非等同的概念。
给定用户查询特征向量和文档特征向量,如何计算其内容相似性?Cosine相似性是最常用也是非常有效的计算相似性的方式。
Cosine公式中的规范化方法有一个明显的缺陷,即存在对长文档的过分抑制:如果同时有相关的短文档和长文档,它会使短文档的相关度数值大大高于长文档的相关度数值。
设想以下情况:一篇短文档,与某主题相关;一篇长文档,除了与这个主题相关之外还讨论了多个其他主题,其中与这个主题相关的部分词频与短文档相仿。在这种情况下,两篇文档中有关这个主题的特征词的权值大致相当,长文档由于包含的索引词很多,文档向量长度比较大,规范化之后有关这个主题的特征词的权重会比短文档小得多。于是,经过相似度计算,短文档得到的相关度数值会比长文档高得多。
3)特征权重计算
文档和查询转换为特征向量时,每个特征都会赋予一定的权值。在向量空间模型里,特征权值的计算框架一般被称做Tf*IDF框架,虽然具体计算方式可以有多种,但是大都遵循这一框架,而这一计算框架考虑的主要计算因子有两个:词频Tf和逆文档频率IDF。
词频因子-TF
Tf计算因子代表了词频,即一个单词在文档中出现的次数,一般来说,在某个文档中反复出现的单词,往往能够表征文档的主题信息,即Tf值越大,越能代表文档所反映的内容,那么应该给予这个单词更大的权值。这是为何引入词频作为计算权值的重要因子的原因。
具体计算词频因子的时候,基于不同的出发点,可以采纳不同的计算公式。最直接的方式就是直接利用词频数,比如文档中某个单词出现过5次,就将这个单词的Tf值计为5。
一种词频因子的变体计算公式是:
W_{tf}=1+log(TF)
即将词频数值Tf取Log值来作为词频权值,比如单词在文档中出现过4次,则其词频因子权值是3,公式中的数字1是为了平滑计算用的,因为如果Tf值为1的情况下,取Log后值为0,即本来出现了一次的单词,按照这种方法计算会认为这个单词从来没有在文档中出现过,为了避免这种情形,采用加1的方式来进行平滑。之所以要对词频取Log,是基于如下考虑:即使一个单词出现了10次,也不应该在计算特征权值时,比出现1次的情况权值大10倍,所以加入Log机制抑制这种过大的差异。
另外一种单词词频因子的变体计算公式是:

这种方法被称为增强型规范化Tf,其中的a是调节因子,过去经验取值0.5,新的研究表明取值为0.4效果更好。公式中的Tf代表这个单词的实际词频数目,而Max(Tf)代表了文档中所有单词中出现次数最多的那个单词对应的词频数目。之所以要如此操作,主要出于对长文档的一种抑制,因为如果文档较长,与短文档相比,则长文档中所有单词的Tf值会普遍比短文档的值高,但是这并不意味着长文档与查询更相关。用单词实际词频除以文档中最高词频,等于将绝对的数值进行了规范化转换,公式的含义就转换为:同一个文档内单词之间的相对重要性。即使一个文档很长,单词词频普遍很高,但是除以文档最高词频,那么通过这种计算方式得出的数值比短文档来说并不一定就大。这样就剔除了文档长度因素的影响,长文档和短文档的词频因子就成为可比的了。
逆文档频率因子-IDF
词频因子是与文档密切相关的,说一个单词的Tf值,指的是这个单词在某个文档中的出现次数,同一个单词在不同文档中Tf值很可能不一样。而逆文档频率因子IDF则与此不同,它代表的是文档集合范围的一种全局因子。给定一个文档集合,那么每个单词的IDF值就唯一确定,跟具体的文档无关。所以IDF考虑的不是文档本身的特征,而是特征单词之间的相对重要性。
所谓逆文档频率因子IDF,其计算公式如下:
IDF_{k}=log{\frac{N}{n_{k}}}
其中的N代表文档集合中总共有多少个文档,而n_{k}代表特征单词k在其中多少个文档中出现过,即文档频率。
由公式可知,文档频率n_{k}越高,则其IDF值越小,即越多的文档包含某个单词,那么其IDF权值越小。IDF反映了一个特征词在整个文档集合中的分布情况,特征词出现在其中的文档数目越多,IDF值越低,这个词区分不同文档的能力越差。
在极端情况下,考虑一个在文档集合中所有文档中都出现的特征词“term”,即n_{k}=N,这说明无论搜索任何主题,“term”这个词都会出现在所有相关和不相关的文档中,因此“term”对任何主题都没有区分相关文档和不相关文档的能力,这时“term”的IDF值为0。
例如,在一个有关计算机领域的文档集合中,特征词“电脑”几乎肯定会出现在所有文档中,这时用它进行搜索没有任何效果。但如果另一个文档集合中包括计算机领域相关的文档和很多有关经济学的文档,那么在这个集合中使用“电脑”搜索计算机相关的文档效果会比较好。也就是说,“电脑”这个特征词在第1个文档集合中区分不同文档的能力很差,在第2个文档集合中区分能力很强。而IDF就是衡量不同单词对文档的区分能力的,其值越高,则其区分不同文档差异的能力越强,反之则区分能力越弱。整体而言,IDF的计算公式是基于经验和直觉的,有研究者进一步分析认为:IDF代表了单词带有的信息量的多少,其值越高,说明其信息含量越多,就越有价值。
Tf*IDF框架
Tf*IDF框架就是结合了上述的词频因子和逆文档频率因子的计算框架,一般是将两者相乘作为特征权值,特征权值越大,则越可能是好的指示词,即:

从上述公式可以看出,对于某个文档D来说:
如果D中某个单词的词频很高,而且这个单词在文档集合的其他文档中很少出现,那么这个单词的权值会很高。
如果D中某个单词的词频很高,但是这个单词在文档集合的其他文档中也经常出现,或者单词词频不高,但是在文档集合的其他文档中很少出现,那么这个单词的权值一般。
如果D中某个单词词频很低,同时这个单词在文档集合的其他文档中经常出现,那么这个单词权值很低。
经过几十年的不断探索,向量空间模型已经相当成熟,并被各种领域广泛采用。从数学模型的角度看,向量空间模型简单直观,用查询和文档之间的相似性来模拟搜索中的相关性。与布尔模型相比,也能对文档与查询的相关性进行打分排序。但是总体而言,向量空间模型是个经验型的模型,是靠直觉和经验不断摸索完善的,缺乏一个明确的理论来指导其改进方向。
3、概率检索模型
概率检索模型是目前效果最好的模型之一,在TREC等各种检索系统评测会议已经证明了这一点,而且okapi BM25这一经典概率模型计算公式已经在商业搜索引擎的网页排序中广泛使用。
1)概率排序原理
概率检索模型是从概率排序原理推导出来的。
概率排序原理的基本思想是:给定一个用户查询,如果搜索系统能够在搜索结果排序时按照文档和用户需求的相关性由高到低排序,那么这个搜索系统的准确性是最优的。而在文档集合的基础上尽可能准确地对这种相关性进行估计则是其核心。
从概率排序原理的表述来看,这是一种直接对用户需求相关性进行建模的方法,这点与向量空间模型不同,向量空间模型是以查询和文档的内容相似性来作为相关性的代替品。
概率排序原理只是一种指导思想,并未阐述如何才能做到这种理想的情形,在这个框架下,怎样对文档与用户需求的相关性建立模型呢?用户发出一个查询请求,如果我们把文档集合划分为两个类别:相关文档子集和不相关文档子集,于是就可以将这种相关性衡量转换为一个分类问题。
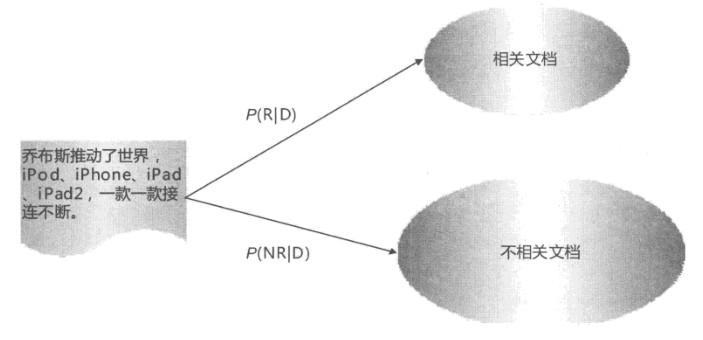
概率模型是一个分类问题
所以现在问题的关键是如何估算P(R|D)和P(NR|D)的数值。为了简化问题,首先我们根据贝叶斯规则对两个概率值进行改写,即:


相关性计算的目的是要判断是否P(R|D)>P(NR|D),将改写公式代入成为如下形式:

因为是同一篇文档,所以右端公式的分母P(D)是相同的,在做相关性判断的时候可消掉,并对因子移项,转换成如下形式:

尽管概率模型将相关性判断转换为一个二值分类问题,但搜索应用并不需要进行真正的分类,而是将搜索结果按照相关性得分由高到低排序,所以对于搜索系统来说只需要将\frac{p(D|R)}{p(D|NR)}大小降序排列即可,于是问题进一步转换成如何估算因子 P(D|R) 和 P(D|NR),而二元独立模型提供了计算这些因子的框架。
2)二元独立模型
为了能够使得估算上述两个计算因子可行,二元独立模型(BIM模型)做出了两个假设:
假设1:二元假设
所谓二元假设,类似于布尔模型中的文档表示方法,一篇文档在由特征进行表示的时候,以特征“出现”和“不出现”两种情况来表示,不考虑词频等其他因素。假设特征集合包含5个单词,某个文档D根据二元假设,表示为{1,0,1,0,1},其含义是这个文档出现了第1个、第3个和第5个单词,但是不包含第2个和第4个单词。做出二元假设是将复杂问题简单化的一种措施。
假设2:词汇独立性假设
所谓词汇独立性假设,是指文档里出现的单词之间没有任何关联,任意一个单词在文档的分布概率不依赖于其他单词是否出现。这个假设很明显和事实不符,比如一篇文档出现了单词“乔布斯”,那么出现“苹果”、“iPad”这些单词的概率显然很大,即单词之间是有依赖性的。但是为了简化计算,很多方法都会做出词汇独立性假设。有了词汇独立性假设,我们就可以将对一个文档的概率估计转换为对文档包含单词的概率估计,因为词汇之间没有关联,所以可以将文档概率转换为单词概率的乘积。
上文提到的文档D表示为{1,0,1,0,1},我们用p_{i}来代表第i个单词在相关文档集合内出现的概率,于是在已知相关文档集合的情况下,观察到文档D的概率为:

因为在文档中出现了第1个、第3个和第5个单词,所以这些单词在相关文档集合中出现的概率为p_{i},而第2个和第4个单词没有出现,那么1-p_{i},就代表了单词不在文档出现的概率,根据词汇独立性假设,将对文档D的概率估计转换为每个单词概率的乘积,这样就可以估算因子P(D|R)。
各种实验表明,根据二元独立模型计算相关性实际效果并不好,但是这个模型却是非常成功的概率模型方法BM25的基础。
3)BM25模型
BIM模型基于二元假设推导而出,即对于单词特征,只考虑是否在文档中出现过,而没有考虑单词的权值。BM25模型在BIM模型基础上,考虑了单词在查询中的权值及单词在文档中的权值,拟合出综合上述考虑因素的公式,并通过实验引入一些经验参数。BM25模型是目前最成功的内容排序模型。
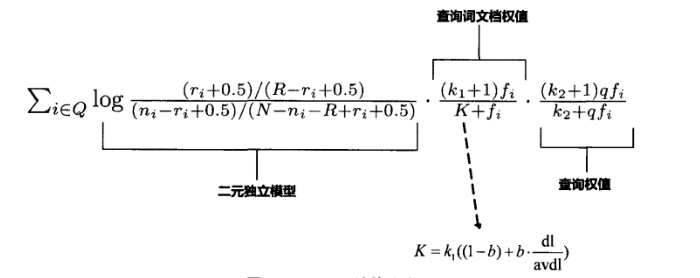
BM25计算公式
对于查询Q中出现的每个查询词,依次计算单词在文档D中的分值,累加后就是文档D与查询Q的相关性得分。从图中可以看出,计算第i个查询词的权值时,计算公式可以拆解为3个组成部分,第1个组成部分就是上节所述的BIM模型计算得分,上节也提到,如果赋予一些默认值的话,这个部分的公式等价于IDF因子的作用;第2个组成部分是查询词在文档D中的权值,其中f代表了单词在文档D中的词频,k_{1}和k_{i}是经验参数;第3个组成部分是查询词自身的权值,其中qf_{i}代表查询词在用户查询中的词频,如果查询较短小的话,这个值往往是1,k_{2}是经验参数。 BM25模型就是融合了这3个计算因子的相关性计算公式。
在第2个计算因子中,K因子代表了对文档长度的考虑,图中所示K的计算公式中,dl代表文档D的长度,而avdl则是文档集合中所有文档的平均长度,k_{1}和b是经验参数。 其中参数b是调节因子,极端情况下,将b设定为0,则文档长度因素将不起作用,经验表明一般将b设定为0.75会获得较好的搜索效果。
BM25公式中包含3个自由调节参数,除了调节因子b外,还有针对词频的调节因子k_{1}和k_{2}。k_{1}的作用是对查询词在文档中的词频进行调节,如果将k_{1}设定为0,则第2部分计算因子成了整数1,即不考虑词频的因素,退化成了BIM模型。如果将k_{1}设定较大值,则第2部分计算因子基本和词频f保持线性增长,即放大了词频的权值,根据经验,一般将k_{1}设定为1.2。调节因子k_{2}和k_{1}的作用类似,不同点在于其是针对查询中的词频进行调节,一般将这个值设定在0到1000较大的范围内,之所以如此,是因为查询往往很短,所以不同查询词的词频都很小,词频之间差异不大,较大的调节参数数值设定范围允许对这种差异进行放大。
综合来看,BM25模型计算公式其实融合了4个考虑因素:IDF因子、文档长度因子、文档词频和查询词频,并利用3个自由调节因子(k1、k2和b)对各种因子的权值进行调整组合。
案例分析:
下面我们以用户查询“乔布斯iPad2”为例子,来看看如何实际利用BM25公式计算某个文档D的相关性。首先假定BM25的第1个计算因子中,我们不知道哪些是相关文档,所以将相关文档个数R和包含查询词的相关文档个数r设定为0,此时第1个计算因子退化成类似于IDF的形式:
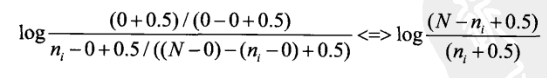
因为查询中两个查询词都只出现了一次,所以其对应的都为1。其他数值假定如下:
文档集合总数N=100000
文档集合中包含单词“乔布斯”的文档个数n_{乔布斯}=1000
文档集合中包含单词“iPad2”的文档个数n_{ipad2}=100
文档D中出现单词“乔布斯”的词频f_{乔布斯}=8
文档D中出现单词“iPad2”的词频f_{ipad2}=5
调节因子k_{1}=1.2
调节因子k_{2}=200
调节因子b=0.75
假定文档长度是平均文档长度的1.5倍,即K=1.2×(0.25+0.75×1.5)=1.65,将这些数值代入BM25计算公式,可以得出文档D和查询的如下相关性得分:
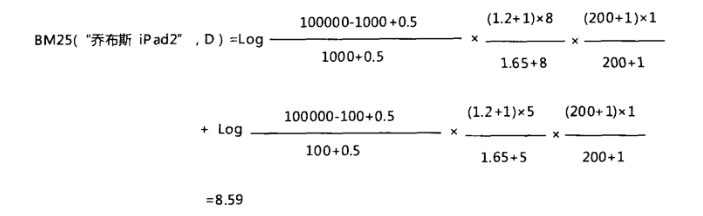
对于文档集合里的所有文档,都按照上述方法计算,将计算结果按照大小排序,就根据BM25公式得出了内容相关性排序。
4)BM25F模型
Okapi BM25模型于1994年提出,之后被广泛研究并应用在不同系统里,也陆续有在此基础上的改进算法出现。2004年推出的BM25F模型就是一个很典型的BM25改进算法。
BM25模型在计算一个文档和查询的相关性的时候,是把文档当做一个整体来看待的,但是在有些应用场景下,需要将文档内容切割成不同的组成部分,然后对不同成分分别对待。最典型的应用场景就是网页搜索,一个网页由页面标题、Meta描述信息、页面内容等不同的“域”(Field)构成,在计算内容相关性得分的时候,往往希望标题的权重大些,因为标题是一个网页的中心思想简述。而BM25由于没有考虑这点,所以不容易做到不同“域”的内容给予不同权重,BM25F就非常适合这种将文档划分为若干“域”,不同“域”需要不同权值的应用场景。
BM25F思路如上,但是不同系统有各异的具体计算方法,本节叙述其中的一种,为了让公式看起来简洁一些,我们用

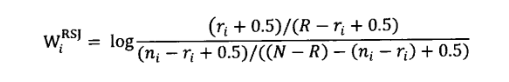
BM25F的计算公式如下:
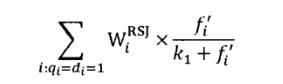
BM25F公式与BM25的区别体现在第2个计算因子中的f_{i}^{l}上,这个因子综合了第i个单词出现在不同“域”的得分,其定义如下:
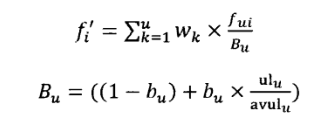
假设一个文档D包含了u个不同的“域”,而每个“域”的权值设定为Wk,f_{i}^{l}将第i个单词在各个不同“域”的分值\frac{f_{ui}}{b_{u}} 加权求和,其中 fui 代表单词在第u个“域”出现的词频数,Bu 则是“域”长度因素。对于Bu来说,ul_{u}是这个“域”的实际长度,avulu 是文档集合中这个“域”的平均长度,而 bu 则是调节因子,这里要注意的一点是:不同的“域” 要设定不同的调节因子,这样搜索效果才好。所以对于BM25F来说,除了调节因子 k1 外,如果文档包含u个不同的“域”,则还需要凭经验设定u个“域”权值和u个长度调节因子。
4、语言模型方法
基于统计语言模型的检索模型于1998年首次提出,是借鉴了语音识别领域采用的语言模型技术,将语言模型和信息检索相互融合的结果。
从基本思路上来说,其他的大多数检索模型的思考路径是从查询到文档,即给定用户查询,如何找出相关的文档。语言模型方法的思路正好相反,是由文档到查询这个方向,即为每个文档建立不同的语言模型,判断由文档生成用户查询的可能性有多大,然后按照这种生成概率由高到低排序,作为搜索结果。
给定了一篇文档和对应的用户查询,如何计算文档生成查询的概率呢?首先,可以为每个文档建立一个语言模型,语言模型代表了单词或者单词序列在文档中的分布情况。我们可以想象从文档的语言模型生成查询类似于从一个装满“单词”的壶中随机抽取,一次抽取一个单词,这样,每个单词都有一个被抽取到的概率。对于查询中的单词来说,每个单词都对应一个抽取概率,将这些单词的抽取概率相乘就是文档生成查询的总体概率。
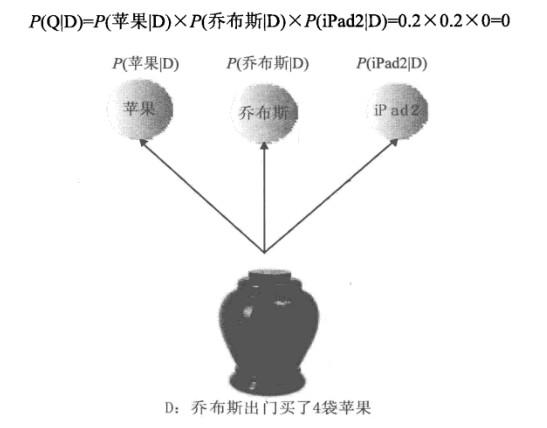
文档D包含5个单词{乔布斯,出门,买了,4袋,苹果},每个单词出现次数都是1次,所以抽取到这5个单词的概率大小相同,都为0.2,这个单词抽取概率分布就是文档D对应的一元语言模型。为文档建立一元语言模型后,即可计算文档D生成用户查询(苹果,乔布斯,iPad2}的概率:
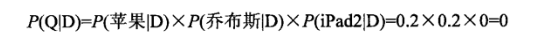
因为文档中出现过“苹果”和“乔布斯”两个单词,其对应的概率都为0.2,但是由于文档D没有出现过单词“iPad2”,所以这个单词的生成概率为0,导致查询整体的生成概率也为0。从这个例子可以看出,由于一个文档文字内容有限,所以很多查询词都没有在文中出现过,这会导致基于语言模型的检索方法失效,这个问题被称做语言模型的数据稀疏问题,是语言模型方法重点需要解决的问题。
一般采用数据平滑的方式解决数据稀疏问题,所谓数据平滑,可以理解为单词分布概率领域的“劫富济贫”,即从文档中出现过的单词的分布概率值中取出一部分,将这些值分配给文档中没有出现过的单词,这样所有单词都有一个非零的概率值,避免计算中出现问题。
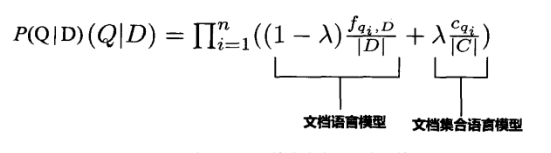
语言模型检索方法则是为所有单词引入一个背景概率来做数据平滑。所谓背景概率,就是给文档集合建立一个整体的语言模型,因为其规模比较大,所以绝大多数查询词都有一个概率值。对于文档集合的一元语言模型,某个单词的背景概率就是这个单词出现的次数除以文档集合的单词总数,这与一个文档计算语言模型是一致的,可以将背景概率的计算理解为:将文档集合内所有文档拼接成一个虚拟的大文档,然后给这个虚拟文档建立语言模型。所以,对于语言模型方法来说,如果文档集合包含N个文档,则需要建立N+1个不同的语言模型,其中每个文档建立自己的语言模型,而文档集合语言模型则作为数据平滑的用处。
文档生成查询概率计算
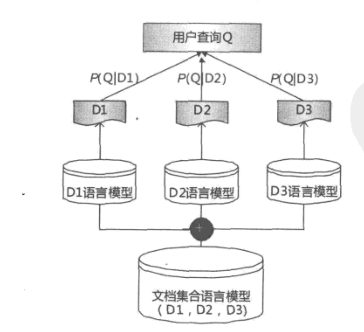
语言模型排序
基于语言模型方法的检索系统对搜索结果排序的示意图,用户提交查询Q,文档集合内所有文档都计算生成Q的概率,然后按照生成概率值由大到小排序,这就是搜索结果。
上述是最基本的语言模型检索方法思路,很多研究在此基础上做出了改进,比如HMM隐马尔科夫语言模型、相关模型、翻译模型等诸多改进模型对基础模型做出了改进。目前各种检索评测证明,语言模型检索方法效果略优于精调参数的向量空间模型,与BM25等概率模型效果相当。
语言模型检索方法从形式上看与向量空间模型和概率模型有很大差异,其实它们之间有密切联系。通过理论推导,可以得出:语言模型检索方法的排序公式符合概率模型的概率排序原理,所以可以归为概率模型的一种。另外,通过一些公式变形推导,可以将其公式转化为类似于向量空间模型的Tf*IDF的形式,这说明了几种模型在利用计算因子方面的一致性。
5、机器学习排序
产生原因
1、随着搜索引擎的发展,对于某个网页进行排序需要考虑的因素越来越多,比如网页的PageRank值、查询和文档匹配的单词个数、网页URL链接地址长度等都对网页排名产生影响,Google目前的网页排序公式考虑了200多种因子,此时机器学习的作用即可发挥出来,这是原因之一。
2、对于有监督机器学习来说,首先需要大量的训练数据,在此基础上才可能自动学习排序模型,单靠人工标注大量的训练数据不太现实。对于搜索引擎来说,尽管无法靠人工来标注大量训练数据,但是用户点击记录是可以当做机器学习方法训练数据的一个替代品,比如用户发出一个查询,搜索引擎返回搜索结果,用户会点击其中某些网页,可以假设用户点击的网页是和用户查询更加相关的页面。尽管这种假设很多时候并不成立,但是实际经验表明使用这种点击数据来训练机器学习系统确实是可行的。
1)机器学习排序的基本思路
传统的检索模型靠人工拟合排序公式,并通过不断的实验确定最佳的参数组合,以此来形成相关性打分函数。机器学习排序与此思路不同,最合理的排序公式由机器自动学习获得,而人则需要给机器学习提供训练数据。
机器学习排序系统由4个步骤组成:人工标注训练数据、文档特征抽取、学习分类函数、在实际搜索系统中采用机器学习模型。
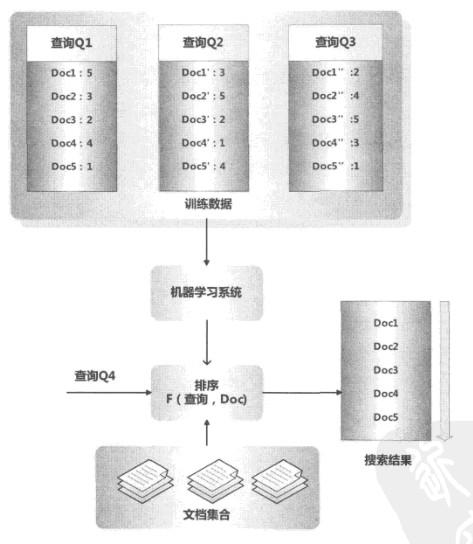
首先,由人工标注训练数据。也就是说,对于某个查询Q,人工标出哪些文档是和这个查询相关的,同时标出相关程度,相关程度有时候可以用数值序列来表示,比如从1分到5分为5个档次,1代表微弱相关,5代表最相关,其他数值代表相关性在两者之间。对于某个查询,可能相关文档众多,同时用户查询也五花八门,所以全部靠人工标注有时候不太可能。此时,可以利用用户点击记录来模拟这种人工打分机制。
对于机器学习系统来说,输入是用户查询和一系列标注好的文档,机器学习系统需要学习打分函数,然后按照打分函数输出搜索结果。但是在其内部,每个文档是由若干特征构成的,即每个文档进入机器学习系统之前,首先需要将其转换为特征向量。比较常用的特征包括:
查询词在文档中的词频信息
查询词的IDF信息
文档长度
网页的入链数量
网页的出链数量
网页的PageRank值
网页的URL长度
杏询词的Proximity值:即在文档中多大的窗口内可以出现所有查询词
以上所列只是影响排序的一部分特征,实际上还有很多类似的特征可以作为特征向量中的一维加入。在确定了特征数量后,即可将文档转换为特征向量X,前面说过每个文档会人工标出其相关性得分Y,这样每个文档会转换为<x,y>的形式,即特征向量及其对应的相关性得分,这样就形成了一个具体的训练实例。
通过多个训练实例,就可以采用机器学习技术来对系统进行训练,训练的结果往往是一个分类函数或者回归函数,在之后的用户搜索中,就可以用这个分类函数对文档进行打分,形成搜索结果。
从目前的研究方法来说,可以将机器学习排序方法分为以下3种:单文档方法、文档对方法和文档列表方法。
2)单文档方法
单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果。
案例分析:我们对于每个文档采用了3个特征:查询与文档的Cosine相似性分值、查询词的Proximity值及页面的PageRank数值,而相关性判断是二元的,即要么相关要么不相关,当然,这里的相关性判断完全可以按照相关程度扩展为多元的,本例为了方便说明做了简化。
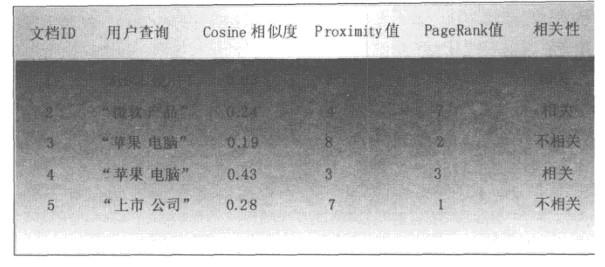
训练数据
例子中提供了5个训练实例,每个训练实例分别标出了其对应的查询,3个特征的得分情况及相关性判断。对于机器学习排序系统来说,根据训练数据,需要学习如下的线性打分函数:
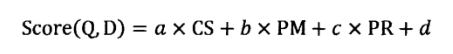
这个公式中,CS代表Cosine相似度变量,PM代表Proximity值变量,PR代表PageRank值变量,而a、b、c、d则是变量对应的参数。如果得分大于一设定阀值,则可以认为是相关的,如果小于设定阀值则可以认为不相关。通过训练实例,可以获得最优的a、b、c、d参数组合,当这些参数确定后,机器学习系统就算学习完毕,之后即可利用这个打分函数来进行相关性判断。对于某个新的查询Q和文档D,系统首先获得其文档D对应的3个特征的特征值,之后利用学习到的参数组合计算两者得分,当得分大于设定的阀值,即可判断文档是相关文档,否则判断为不相关文档。
3)文档对方法
对于搜索任务来说,系统接收到用户查询后,返回相关文档列表,所以问题的关键是确定文档之间的先后顺序关系。单文档方法完全从单个文档的分类得分角度计算,没有考虑文档之间的顺序关系。文档对方法则将重点转向了对文档顺序关系是否合理进行判断。
之所以被称为文档对方法,是因为这种机器学习方法的训练过程和训练目标,是判断任意两个文档组成的文档对<Doc1,Doc2>是否满足顺序关系,即判断是否Doc1应该排在Doc2的前面。
实例:
查询Q1对应的搜索结果列表如何转换为文档对的形式,因为从人工标注的相关性得分可以看出,Doc2得分最高,Doc3次之,Doc1得分最低,于是我们可以按照得分大小顺序关系得到3个如图所示的文档对,将每个文档对的文档转换为特征向量后,就形成了一个具体的训练实例。
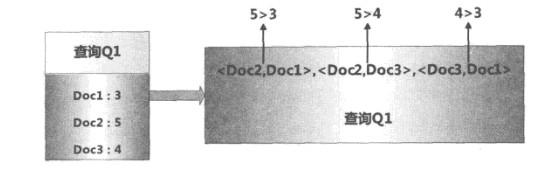
根据转换后的训练实例,就可以利用机器学习方法进行分类函数的学习,具体的学习方法有很多,比如SVM、Boost、神经网络等都可以作为具体的学习方法,但是不论具体方法是什么,其学习目标都是一致的,即输入一个查询和文档对<Doc1,,Doc2>,机器学习排序能够判断这种顺序关系是否成立,如果成立,那么在搜索结果中Doc1应该排在Doc2前面,否则Doc2应该排在Doc1前面。通过这种方式,就完成搜索结果的排序任务。
尽管文档对方法相对单文档方法做出了改进,但是这种方法也存在两个明显的问题。
一个问题是:文档对方法只考虑了两个文档对的相对先后顺序,却没有考虑文档出现在搜索列表中的位置。排在搜索结果前列的文档更为重要,如果前列文档出现判断错误,代价明显高于排在后面的文档。针对这个问题的改进思路是引入代价敏感因素,即每个文档对根据其在列表中的顺序具有不同的权重,越是排在前列的权重越大,即在搜索列表前列如果排错顺序的话其付出的代价更高。
另外一个问题是:不同的查询,其相关文档数量差异很大,所以转换为文档对之后,有的查询可能有几百个对应的文档对,而有的查询只有十几个对应的文档对,这对机器学习系统的效果评价造成困难。我们设想有两个查询,查询Q1对应500个文档对,查询Q2对应10个文档对,假设学习系统对于查询Q1的文档对能够判断正确480个,对于查询Q2的文档对能够判断正确2个,如果从总的文档对数量来看,这个学习系统的准确率是(480+2)/(500+10)=0.95,即95%的准确率,但是从查询的角度,两个查询对应的准确率分别为:96%和20%,两者平均为58%,与纯粹从文档对判断的准确率相差甚远,这对如何继续调优机器学习系统会带来困扰。
4)文档列表方法
单文档方法将训练集里每一个文档当做一个训练实例,文档对方法将同一个查询的搜索结果里任意两个文档对作为一个训练实例,文档列表方法与上述两种表示方式不同,是将每一个查询对应的所有搜索结果列表整体作为一个训练实例,这也是为何称之为文档列表方法的原因。
文档列表方法根据K个训练实例(一个查询及其对应的所有搜索结果评分作为一个实例)训练得到最优评分函数F,对于一个新的用户查询,函数F对每一个文档打分,之后按照得分顺序由高到低排序,就是对应的搜索结果。
所以关键问题是:拿到训练数据,如何才能训练得到最优的打分函数?
一种训练方法,它是基于搜索结果排列组合的概率分布情况来训练的。首先解释下什么是搜索结果排列组合的概率分布,我们知道,对于搜索引擎来说,用户输入查询Q,搜索引擎返回搜索结果,我们假设搜索结果集合包含A、B和C 3个文档,搜索引擎要对搜索结果排序,而这3个文档的顺序共有6种排列组合方式: ABC,ACB,BAC,BCA,CAB和CBA,而每种排列组合都是一种可能的搜索结果排序方法。
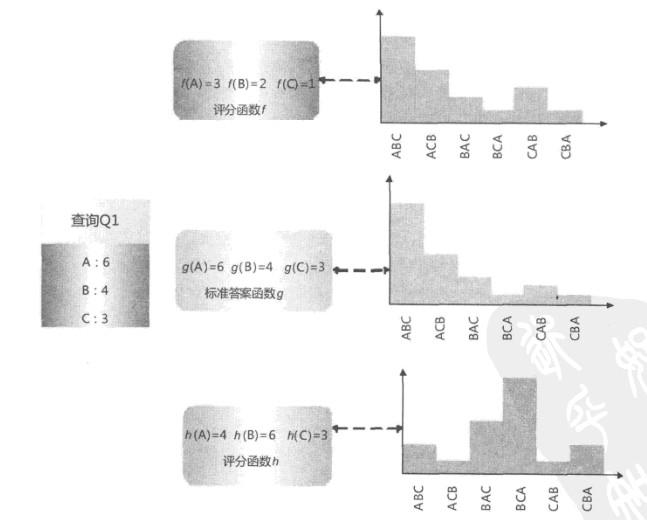
不同评分函数的KL距离
对于某个评分函数F来说,对3个搜索结果文档的相关性打分,得到3个不同的相关度得分F(A)、F(B)和F(C),根据这3个得分就可以计算6种排列组合情况各自的概率值。不同的评分函数,其6种搜索结果排列组合的概率分布是不一样的。
经验结果表明,基于文档列表方法的机器学习排序效果要好于前述两种方法。
6、检索质量评价标准
在搜索系统最终推出之前,一般都要对其性能进行评测。除了时间和空间等运行效率方面的评测外,更重要的是对搜索结果质量进行评测。研发人员可以根据测试结果选择效果较好的搜索技术,或验证搜索系统在真实环境中运行时的实际效果,以辅助系统不断进行设计、研究和改进。因此搜索系统的性能评测对于系统的研制和发展是至关重要的。
如何评价搜索结果质量呢?最广为接受的评价标准是用精确率和召回率这两个指标来评价搜索质量。
1)精确率与召回率
给定一个固定的用户搜索请求,搜索系统将系统认为和用户请求相关的文档返回给用户。对于这次搜索行为,可以根据两个维度来将所有文档构成的集合划分成4个互不相交的子集。
1个维度是:“该文档是否与用户发出的搜索请求相关”,由此维度,可以将整个文档集合划分为相关与不相关两种类型;
第2个维度是:“文档是否在本次搜索结果列表里”,由此维度,可以将整个文档集合划分为“在本次搜索结果列表”与“不在本次搜索结果列表”两种类型
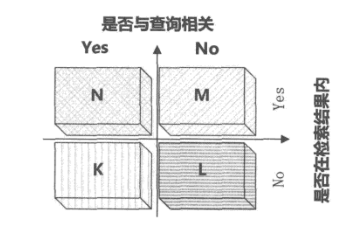
将以上两个划分维度组合,把文档集合切割为4个互不相交的子集。左上角的子集代表“在本次搜索结果中与搜索请求相关”的文档,假设集合大小为N;右上角的子集代表“在本次搜索结果中与搜索请求不相关”的文档,假设集合大小为M;左下角的子集代表“在本次搜索结果之外与搜索请求相关”的文档,即那些本来应该由搜索系统返回但因为算法原因没有找到的相关文档,假设集合大小为K;右下角的子集代表“在本次搜索结果之外且与搜索请求无关”的文档,假设集合大小为L。
在将文档集合划分为4个子集的基础上,我们可以对精确率和召回率进行定量描述。
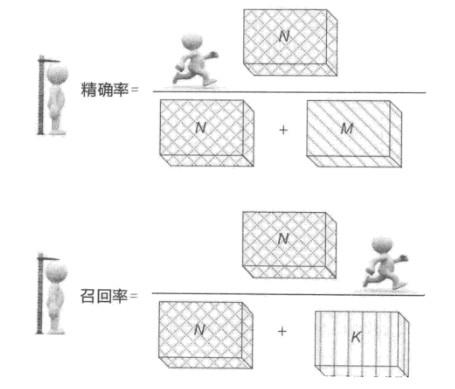
精确率,就是本次搜索结果中相关文档所占的比例,分子为本次搜索结果中的相关文档(左上角子集),分母为本次搜索结果包含的所有文档(第1行),两者相除得到精确率。
召回率,即本次搜索结果中包含的相关文档占整个集合中所有相关文档的比例,分子与精确率分子相同,即本次搜索结果中包含的相关文档,分母为整个文档集合所包含的所有相关文档(第1列),两者相除得到召回率。召回率用于评价搜索系统是否把该找出的文档都找出来了。
精确率和召回率是常见的评估检索系统的指标,但是对于搜索引擎来说,精确率更为重要,因为搜索引擎处理海量数据,一方面在这种环境下,对于某个查询,找到与这个查询相关的所有文档(也即计算召回率公式的分母)难度很大,导致召回率很难准确计算;另外一方面由于数据量比较大,所以能够满足用户需求的文档量也很大,用户很少需要看到所有相关文档,往往是看到一部分即可满足搜索需求,全部召回相关文档对于满足用户需求意义也不是特别重要。而相对应地,精确率在搜索引擎场景下就非常重要了,因为排在搜索列表前列的搜索结果如果有太多不相关的内容,直接影响用户体验,所以对于搜索引擎质量评估来说,往往更加关注精确率。
在具体评估时,需要做更加精细的考虑。常用的评估搜索引擎精度的指标有P@10和MAP。
2)P@10指标
p@10指标更关注搜索结果排名最靠前文档的结果质量,它用于评估在搜索结果排名最靠前的头10个文档中有多大比例是相关的。
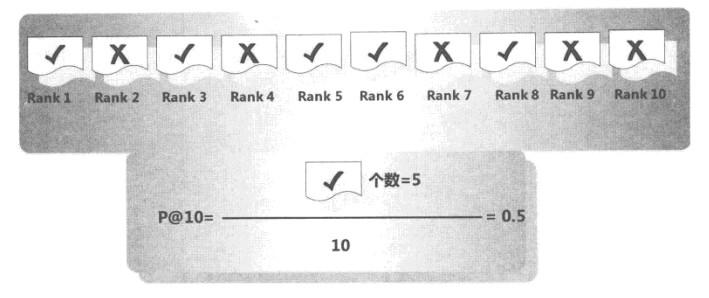
打对钩的文档代表与用户查询相关,叉号代表无关,在这个例子中,头10个文档中包含了5个相关文档,所以其精度为0.5。
3)MAP指标
MAP指标是针对多次查询的平均准确率衡量标准,是评价检索系统质量的常用指标。
要了解MAP,首先需要了解AP(Average Precision)。MAP是衡量多个查询的平均检索质量的,而AP是衡量单个查询的检索质量的。
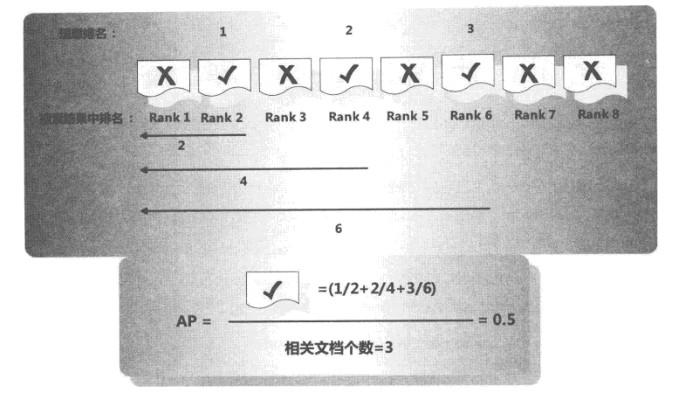
AP计算过程
例子中假设与用户查询相关的文档有3个,经过搜索系统输出后,分别排在搜索结果的第2位、第4位和第6位,如果是一个理想的搜索系统,理论上应该将这3个文档排在第1位、第2位和第3位,所以用这3个文档的理想排名位置除以实际排名位置,会得到每个文档的得分,3个文档求平均值得到本次搜索的AP值0.5。AP值越高,则意味着越接近理想的搜索结果,说明检索系统质量越好。如果例子中的3个相关文档分别处于搜索结果的第1位、第2位和第3位,那么AP值为1,这就是理想的搜索结果。AP指标兼顾了排在前列结果的相关性和系统召回率,这是为何被经常采用的原因。
AP是针对单次查询的衡量指标,如果存在多组查询,那么每个查询都会有自己的AP值,对这些查询的AP值求平均值,就得到了MAP指标。
相关文章
-
搜索引擎核心技术详解4—索引压缩
-
搜索引擎核心技术详解10—网页去重
-

搜索引擎核心技术详解8—网页反作弊
-
搜索引擎核心技术详解6—链接分析
-

搜索引擎核心技术详解3—搜索引擎索引
-
搜索引擎核心技术详解2—网络爬虫
-
搜索引擎核心技术详解1—搜索引擎及其技术架构

")
")
发表评论